ANTLR Basics - Writing Grammar
ANTLR란?
ANTLR (ANother Tool for Language Recognition)는 parser 생성기이다. Parser는 분석하고자 하는 텍스트를 읽어와 그것을 parse tree, 즉 Anstract Syntax Tree(AST)의 조직화된 구조로 변경시켜준다.
이러한 parse tree를 만들기 위해서는,
- lexer/parser grammar를 정의하고
- ANTLR를 호출한다 - 타겟 언어(Java, Python, C#, etc)로 lexer와 parser를 생성한다.
- 생성된 lexer와 parser를 사용한다 - 이 둘을 호출해서 parse tree를 리턴하도록 한다.
Setup ANTLR
https://www.antlr.org/download/antlr-4.9.2-complete.jar 현재 기준 가장 최신 버전의 ANTLR를 위 사이트에서 다운로드한다.
윈도우의 경우, D:\Program Files\Java\extlibs 디렉토리를 만들어서 jar파일을 넣은 후 시스템 변수에 CLASSPATH를 .;D:\Program Files\Java\extlibs\antlr-4.9.2-complete.jar로 설정하였다.
Command Line에서 ANTLR를 편하게 실행하기 위해 PATH에 batch 파일 두 개를 넣어줄 것이다. D:\Program Files\Java\extlibs를 PATH variable에 추가시켜준다.
그 다음, 해당 디렉토리에서 antlr4.bat을 생성해주고
java org.antlr.v4.Tool %*
를 입력하고, grun.bat을 생성한 후
java org.antlr.v4.runtime.misc.TestRig %*
를 입력한 후 저장한다.
커맨드 창을 열어서 antlr4와 grun을 입력했을 때 잘 실행이 되는지 확인한다.
WorkFlow
첫번째로 할 일은 분석 하고자 하는 언어의 룰을 정의 해놓은 grammar 파일(.g4 확장자)을 작성하는 것이다. 그 후에 antlr4 프로그램을 사용하여 내 프로그램이 실제로 사용할 lexer와 parser를 생성하게 된다.
antlr4 <options> <grammar-file-g4>
몇 가지 option을 줄 수 있는데, 먼저 target 언어를 명시할 수 있다 - DEFAULT는 Java 또, visitor와 listener를 생성하기 위해 옵션을 줄 수 있는데, DEFAULT로는 listener를 생선한다 - visitor를 생성하려면 -visitor 커맨드를 추가, listener를 생성하지 않으려면 -no-listener 커맨드 추가
grammer를 TestRig(grun으로 alias 지정함)라는 유틸리티로 다음과 같이 테스트해볼 수 있다.
grun <grammer-name> <rule-to-test> <input-filename(s)>
filename(s)은 선택 사항이고 콘솔 입력값을 분석할 수도 있다. grun은 grammer 초안을 테스트할 때 유용하게 쓰이고 나중에는 자동화 시키는 것이 좋다.
Java Setup
ANTLR를 사용하여 Java Project를 셋업하기 위해서 Gradle을 사용한 예시를 보겠다. IDE에서 Plugin을 설치해도 좋다. Gradle plugin을 사용하여 ANTLR를 호출한다.
plugins {
id 'java'
id 'antlr'
id 'idea'
}
repositories {
mavenCentral()
jcenter()
}
dependencies {
antlr "org.antlr:antlr4:4.9.2"
compile "org.antlr:antlr4-runtime:4.9.2"
testImplementation(platform('org.junit:junit-bom:5.7.0'))
testImplementation('org.junit.jupiter:junit-jupiter')
}
generateGrammarSource {
maxHeapSize = "128m"
arguments += ['-package', 'com.company.MarkupParser', '-visitor', '-no-listener']
}
compileJava.dependsOn generateGrammarSource
sourceSets {
generated {
java.srcDir 'generated-src/antlr/main/'
}
}
compileJava.source sourceSets.generated.java, sourceSets.main.java
clean{
delete "generated-src"
}
idea {
module {
sourceDirs += file("generated-src/antlr/main/")
}
}
test {
useJUnitPlatform()
testLogging {
events "passed", "skipped", "failed"
}
}grammar 파일들은 src/main/antlr/에 보관한다.
이제 다음 커맨드를 실행하여 grammar 파일로부터 lexer와 parser를 생성할 수 있다.
gradlew generateGrammarSource
또, 다음을 실행하면 Intellij(IDEA) Project가 준비된다.
gradlew idea
Lexer와 Parser
Lexer, 혹은 tokenizer는 각각의 character를 가지고 토큰으로 변환시켜준다. 그리고 parser는 이 토큰들을 가지고 논리적인 구조를 만들게 된다. 예를 들어 다음과 같은 연산이 있을 때 lexer와 parser가 수행하는 과정을 볼 수 있다.

여기서 lexer는 텍스트를 스캔하면서 ‘4’, ‘3’, ‘7’을 숫자로, ‘ ‘는 공백으로, 그리고 ‘+’는 연산자로 인식을 하게된다. 왜냐하면 이에 대한 룰을 우리가 정할 수 있기 때문이다.
/*
* Parser Rules
*/
operation : NUMBER '+' NUMBER ;
/*
* Lexer Rules
*/
NUMBER : [0-9]+ ;
WHITESPACE : ' ' -> skip ;
룰은 전형적으로 parser rule 다음에 lexer rule 순서로 적는다. (실제로는 반대 순서로 적용되지만) 또, lexer rule은 보이는 순서대로 분석이 되고 ambiguous할 수도 있다.
대표적인 예시로 식별자(identifier)의 경우이다 - 대부분의 프로그래밍 언어에서는 임의의 문자열 형태를 가질 수 있지만 “class”나 “function”과 같이 특정 조합은 사용할 수 없다. 따라서 이러한 ambiguity를 해결하기 위해 룰의 순서로 인해 first match가 사용되게 된다. 그렇기 때문에 class나 function 키워드가 먼저 정의되고 식별자는 나중에 정의된다.
룰의 Syntax: 이름 : 룰 정의 ;
예를 들어 NUMBER는 range of digits와 한 개 이상의 match가 허용된다는 의미를 가지는 ‘+’로 정의된다. WHITESPACE의 경우 ANTLR에게 어떠한 것을 무시하는 것에 대한 룰을 명시한다. 만약에 이런식으로 공백을 무시하는 룰이 없었다면 parser 룰이 다음과 같이 바뀔 것이다.
operation : WHITESPACE* NUMBER WHITESPACE* '+' WHITESPACE* NUMBER;
Grammar 만들기
Grammar를 작성하기 위해서는 top-down과 bottom-up approach가 존재한다.
Top-down Approach
이 방식은 내 특정 언어로 작성된 파일의 일반적인 구조를 보고 시작하게 된다.
- 파일의 메인 섹션이 무엇인지?
- 그것들의 순서는 어떻게 되는지?
- 각각의 section에 뭐가 있는지?
예를 들어 Java 파일은,
- package 선언
- imports
- type definitions 이 세가지 섹션으로 나뉠 수 있다.
이 방식은 그 언어나 형식에 대해 이미 잘 알고 있고 이론적인 지식이 충분히 있을 때, 혹은 “큰 그림”부터 시작하고자 할 때 가장 효과적이다. 따라서 전체 파일을 표현하는 룰을 정의하며 시작한다. 즉, 가장 일반적이고 추상적인 것부터 시작해서 점점 low-level로 정의하게 된다.
Bottom-up Approach
반대로 bottom-up 방식은 작은 요소부터 시작한다. 토큰들이 어떻게 capture되는지 정의하고 기본 표현식이 어떻게 정의되는지 등등.. 그 후 점점 high-level로 가서 전체 파일을 표현하는 룰을 정의하게 된다.
새로운 문법을 만들다
새로운 언어의 문법을 정의하는 것은 힘든 일이다. 사용자도 쉽게 알 수 있어야 하며 애매모호해서는 안된다. 따라서 우리는 간단한 채팅 프로그램을 위한 grammar를 만들어 보고자 한다.
목표
- 문단은 없다. 메시지들 간에는 newline만이 separator가 된다.
- 이모티콘, 멘션(mention), 링크 기능을 허용한다. HTML 태그는 지원하지 않는다.
- 질풍노도 시기의 사춘기 학생들을 위한 채팅 앱이므로 소리지를 수 있는 “SHOUT” 기능과 텍스트 색상 변경 기능을 제공한다.
Lexer Rules
기본 Syntax는 다음과 같다.
| Syntax | Meaning |
|---|---|
A |
Match lexer rule or fragment named A |
A B |
Match A followed by B |
(A|B) |
Match either A or B |
'text' |
Match literal “text” |
A? |
Match A zero or one time |
A* |
Match A zero or more times |
A+ |
Match A one or more times |
[A-Z0-9] |
Match one character in the defined ranges (A-Z or 0-9) |
'a' .. 'z' |
Alternative syntax for a character range |
~[A-Z] |
Negation of a range - match any single character not in the range |
. |
Match any single character |
/*
* Lexer Rules
*/
fragment A : ('A'|'a') ;
fragment S : ('S'|'s') ;
fragment Y : ('Y'|'y') ;
fragment H : ('H'|'h') ;
fragment O : ('O'|'o') ;
fragment U : ('U'|'u') ;
fragment T : ('T'|'t') ;
fragment LOWERCASE : [a-z] ;
fragment UPPERCASE : [A-Z] ;
SAYS : S A Y S ;
SHOUTS : S H O U T S;
WORD : (LOWERCASE | UPPERCASE | '_')+ ;
WHITESPACE : (' ' | '\t') ;
NEWLINE : ('\r'? '\n' | '\r')+ ;
TEXT : ~[\])]+ ;
우리는 fragment라는 것을 사용할 것이다. 이는 재사용 가능한 lexer 룰의 빌딩 블록이다. 한 번 정의하고 참조해서 사용할 수 있다.
키워드에서 사용하고자 하는 letter에 대한 fragment를 정의한다. 왜냐하면 case-insensitive한 키워드도 지원하기 위해서이다.
Parser Rules
이제 우리의 프로그램이 가장 많이 인터렉션을 하는 parser 룰을 정의해본다.
/*
* Parser Rules
*/
chat : line+ EOF ;
line : name command message NEWLINE;
message : (emoticon | link | color | mention | WORD | WHITESPACE)+ ;
name : WORD WHITESPACE;
command : (SAYS | SHOUTS) ':' WHITESPACE ;
emoticon : ':' '-'? ')'
| ':' '-'? '('
;
link : '[' TEXT ']' '(' TEXT ')' ;
color : '/' WORD '/' message '/';
mention : '@' WORD ;
먼저 message를 보면, message는 리스트된 룰들이 어떤 순서의 조합으로 오던 간에 match될 수 있다. 이는 whitespace를 반복해서 명시하지 않게 하는 방법 중 하나이다. 예를 들어 WORD WORD mention을 parser가 보기에는 WORD WHITESPACE WORD WHITESPACE mention WHITESPACE로 보기 떄문이다.
command 룰은 간단하다. command의 두 가지 옵션과 콜론사이에 공백이 있으면 안되지만 콜론 다음에는 한 개가 있어야 한다.
emoticon 룰을 보면 happy face / sad face 두 가지가 가능하다. (‘-‘는 없어도 됨)
NOTE: Parser는 semantics를 검사하지 않는다! 다시말해 color의 WORD가 유의미한 색깔인지 parser는 모른다. “red”대신에 “dog”를 입력해도 뭐가 옳고 그른지를 모르기 떄문에 이는 프로그램의 로직에 의해 검사되어야 한다. 따라서, grammar와 로직 코드에서의 검사를 어떻게 나눌지를 잘 생각해야 한다.
Parser는 syntax만 검사하여야하고 semantics는 프로그램에서 검사한다.
Mistakes and Adjustments
우리가 작성한 grammar를 시도해보기 전에 파일 맨 앞에 이름을 추가해줘야 한다. (파일 이름과 동일해야 함)
grammar Chat;
그 후, Java 코드가 생성되면 테스트 툴을 돌려본다.
$ antlr4 Chat.g4
$ javac Chat*.java
// grun이 testing tool, Chat은 grammar 이름, chat은 parse하고자 하는 룰
$ grun Chat chat
> john SAYS: hello @michael this will not work
> CTRL+D(Linux)/CTRL+Z(Windows)
- line 1:0 mismatched input 'john SAYS: hello @michael this will not work' expecting WORDWORD가 없다고 불만을 표시한다. -tokens 옵션을 통해 인식된 토큰을 찾아본다.
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:44='john SAYS: hello @michael this will not work',<TEXT>,1:0]
- [@1,45:44='<EOF>',<EOF>,2:0] ANTLR가 TEXT 토큰만 인식한다. ANTLR는 항상 가장 큰 토큰을 매칭시키려 한다. 그리고 위 커맨드는 유효한 TEXT 값이된다. 이를 해결하기 위해 우리는 다음과 같은 변화를 준다.
[..]
link : TEXT TEXT ;
[..]
TEXT : ('['|'(') ~[\])]+ (']'|')');
TEXT가 ‘[’, ‘(‘로 시작하게 만들 수 있다.
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:3='john',<WORD>,1:0]
- [@1,4:4=' ',<WHITESPACE>,1:4]
- [@2,5:8='SAYS',<SAYS>,1:5]
- [@3,9:9=':',<':'>,1:9]
- [@4,10:10=' ',<WHITESPACE>,1:10]
- [@5,11:15='hello',<WORD>,1:11]
- [@6,16:16=' ',<WHITESPACE>,1:16]
- [@7,17:17='@',<'@'>,1:17]
- [@8,18:24='michael',<WORD>,1:18]
- [@9,25:25=' ',<WHITESPACE>,1:25]
- [@10,26:29='this',<WORD>,1:26]
- [@11,30:30=' ',<WHITESPACE>,1:30]
- [@12,31:34='will',<WORD>,1:31]
- [@13,35:35=' ',<WHITESPACE>,1:35]
- [@14,36:38='not',<WORD>,1:36]
- [@15,39:39=' ',<WHITESPACE>,1:39]
- [@16,40:43='work',<WORD>,1:40]
- [@17,44:44='\n',<NEWLINE>,1:44]
- [@18,45:44='<EOF>',<EOF>,2:0]
-gui 옵션을 사용하여 트리 형태로 parsing 결과를 볼 수 있다.
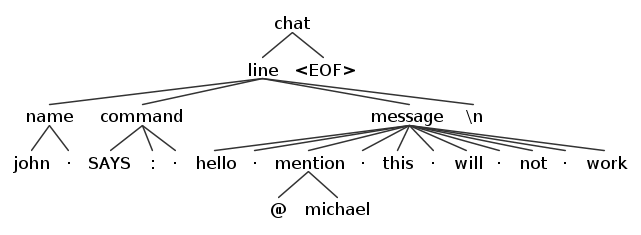
NOTE: ‘.’은 공백을 의미한다.
출처: https://tomassetti.me/antlr-mega-tutorial/
Leave a comment