ASM - Java Bytecode Manipulation Framework
Java Bytecode
우리가 Java 소스 코드를 컴파일한다는 것은, Java 컴파일러(javac)를 통해 .java 파일이 바이트코드인 .class 파일로 컴파일되는 것을 말한다. 그리고 그 후, 이 바이트코드는 JVM에 의해 interpret되어 프로그램이 실행된다. 이 바이트코드는 Java Runtime Enviroment(JRE)가 있는 모든 컴퓨터에서 실행될 수 있다.
Java 클래스 파일 형식
Java 클래스 파일은 일반적으로 트리 구조로 나타낸다. 트리의 루트 노드는 다음의 노드들을 같는다. (*는 0 이상을 나타냄)
- ConstantPool: 심볼 테이블
- FieldInfo*: 클래스의 필드들에 대한 정보
- MethodInfo*: 클래스의 메소드들에 대한 정보
- Attribute*: 선택적 추가적인 노드들
FieldInfo
FieldInfo 노드는 필드의 이름, 타입, 제어자 관련 플래그를 포함한다. 또한, 선택적 추가적인 속성(attribute)들을 가질 수 있다. 여기서 속성은 그것의 타입과 크기가 명시적으로 저장된 노드를 말한다. 속성 노드 중에 ConstantValue 속성은 constant static 필드의 값을 저장할 수 있다. Deprecated 속성은 필드의 deprecation 여부를 나타내고, Synthetic 속성은 컴파일러에 의해 생성된 필드인지의 여부를 나타낸다.
MethodInfo 노드는 메소드의 이름, 파라미터들의 타입, 리턴 타입, 그리고 제어자 관련 플래그를 포함한다. 가장 중요한 요소가 Code 속성인데, 이는 non-abstract 메소드의 코드를 포함한다. Exceptions 속성은 메소드가 던질 수 있는 예외들의 이름을 포함한다. Deprecated와 Synthetic 속성은 FieldInfo와 동일하게 적용된다.
루트 노드의 선택적 속성 노드들은 SourceFile 속성, InnerClasses 속성, 그리고 Deprecated 속성이 있다.
심볼 테이블
클래스의 심볼 테이블, 즉 ConstantPool은 숫자와 문자열 상수를 담고 있는 배열이다. 그리고, 이러한 상수들을 서로 조합하여 새로운 상수들을 만들어 저장하게 되고, 클래스 트리의 다른 노드들은 이 상수들의 배열 인덱스를 통해 참조할 수 있다.
심볼 테이블의 목표는 중복성(redundancy)을 피하기 위해서이다. 예를 들어, FieldInfo는 특정 필드의 이름을 직접적으로 포함하지 않고, 심볼 테이블에 있는 해당 이름의 인덱스를 가진다. 비슷하게, GETFIELD와 PUTFIELD 명령어는 읽어야 하거나 쓰여야 하는 필드의 이름을 직접적으로 가지지 않고 이름의 인덱스를 가진다. 따라서 필드의 이름이 여러 명령들에 의해 여러 번 참조된다고 하여도, 단 한 번만 저장된다.
메소드 코드
메소드의 코드는 Code 속성에 저장된다. 메소드 코드는 기본적인 명령어들의 순서를 갖춘 목록(ordered list)으로써, 주로 스택 개념으로 추상화된다. 그러나 레지스터 개념과 같은 로컬 변수 개념을 기반으로 할 수도 있다. 대부분의 명령어들은 각 한 바이트로 코딩되고, 인수(argument)를 가지지 않는다 - 그래서 바이트코드 명령어라고 불리는 것이다.
Code 속성은 또 예외 처리 테이블, - 이는 Java의 try, catch, finally 블록들에 해당된다 - 그리고 메소드 실행에 대한 최대 스택 크기를 나타내는 정수를 가진다. 또한, 선택적 추가적인 부속성(sub-attribute)들을 가질 수 있다. 예를 들어, LineNumberTable 속성은 각 바이트코드 명령어가 소스 코드 상에 몇 번째 줄에 대응되는지에 대한 정보를 담고 있다. 그리고 LocalVariableTable 속성은 메소드의 formal 매개변수들의 이름과 메소드에 선언된 로컬 변수들의 이름을 담고 있다.
클래스 조작의 어려운 점들
Java 클래스를 조작하는데 있어서 주 어려운 점은, 컴파일된 클래스 파일은 단순히 바이트들의 배열이기 때문에 직접적으로 변경하는 것은 거의 불가능하다는 점이다. 실제로는 컴파일된 클래스의 트리 구조를 분석하기 위해 클래스 파일을 읽는 것 조차도 어려운 일이다.
또 다른 문제점은, 심볼 테이블 참조자들을 갱신하는 일이다. 예를 들어, 테이블에서 어떠한 상수가 삭제되거나 추가된다면, 그 다음에 오는 상수들의 인덱스가 하나 씩 증가 혹은 감소되어야 할 것이다. 따라서 이 상수들을 참조하는 클래스에 있는 모든 참조자들을 모두 업데이트해야 한다. 게다가, 클래스 변경 후, 더 이상 사용되지 않는 상수들이 생긴다면, 이는 클래스를 전체적으로 분석해야 다 잡을 수 있을 것이고 그 후에 테이블을 업데이트 할 수 있을 것이다.
더 나아가, GOTO나 IFEQ와 같은 몇몇 명령어들에 포함된 상대/절대 명령어 주소들을 갱신하는 것도 어렵다. LineNumberTable이나 LocalVariableTable 속성 갱신도 마찬가지이다. 명령어가 메소드에서 추가되거나 삭제되면, 이러한 명령어들의 주소가 변경될 것이다.
마지막 문제점은, 메소드의 최대 스택 크기를 나타내는 정수를 생신하는 일이다. 최대 스택 크기는 메소드의 글로벌 속성으로써 일반적으로, 원래 코드에 대한 최대 스택 크기와 변경의 특징을 통해 변경된 메소드의 최대 스택 크기를 구하는 것은 불가능하다. 변경된 코드를 Control Flow 분석 알고리즘을 통해 전체적으로 분석해서 새로운 최대 스택 크기를 구해야만 한다.
기존의 접근법들
NOTE: 앞으로 사용되는 객체화(Object Representation)라는 용어는, 변경하고자 하는 클래스 파일 정보를 하나의 객체로 표현하는 것을 의미한다.
BCEL
BCEL에서 클래스 변경은 세 가지 단계로 진행된다. 첫 번째 단계에서, 클래스를 나타내는 바이트 배열이 역직렬화되고, 이 클래스의 구조에 대응되는 객체 모델이 메모리에 생성된다. 이 구조에 있는 노드들에 대해 바이트코드 명령어 단위까지 각각 객체가 생성된다. 즉, 하나의 바이트코드 명령어에 대해 한 개의 객체가 생성된다.
두 번째 단계에서, 이렇게 생성된 객체들을 조작한다. 세 번째 단계에서는 변경된 객체 그래프를 새로운 바이트 배열로 직렬화한다. 변경말고 새롭게 클래스를 만드는 것도 비슷하다 - 해당 클래스에 대응되는 객체 모델을 만들고 직렬화한다.
이 접근법은 내부적으로 직렬화와 역직렬화를 툴이 알아서 해주기 때문에 사용자는 객체화된 클래스를 조작만하면 되고, 직렬화와 역질렬화를 신경쓰지 않아도 된다.
그러나, 심볼 테이블 관리와 관련된 문제는 해결해주지 못한다. 왜냐하면 사용자가 심볼 테이블에 있는 상수에 대한 인덱스를 명시해야만 하고, 상수들에 변경이 있을 경우, 인덱스들을 수동으로 업데이트해야 한다. 그러나 실제로 이러한 일은 자주 일어나지 않는다. 왜냐하면 BCEL은 상수를 제거할 수 있는 가능성을 제공하지 않기 때문이다. 상수가 추가가 될 때는, 심볼 테이블 끝에 상수가 더해지는 것이므로 나머지 인덱스들은 그대로 유지된다. 단, 상수를 제거할 수 있는 유일한 방법은 심볼 테이블 전체가 새로운 테이블로 교체되는 예외 상황이다.
반면에, BCEL은 명령어 주소 관리 문제는 해결하였다. 바이트 수로 저장된 상대적 혹은 절대적 주소값을 역직렬화 과정에서 바이트코드 명령어를 나타내는 Java 객체에 대한 참조값으로 대체하였다. 이 참조값은 직렬화 과정에서만 바이트 오프셋으로 변환되기 때문에, 명령어가 추가되거나 삭제될 때 사용자가 매번 주소값을 변경할 필요가 없다.
또, BCEL은 메소드의 최대 스택 크기를 계산할 수 있는 함수를 제공한다. 이 함수는 Control Flow 알고리즘을 기반으로하고, 메소드의 모든 변경이 끝난 후에, 직렬화 과정 전에 호출되어야 한다.
SERP
SERP는 클래스를 객체화한다는 점에서 BCEL과 유사하다. 그러나 SERP는 더 적은 수의 클래스들을 사용하여, 좀 더 간소화된 버전으로 볼 수 있다.
BCEL과 비슷하게 문제점들에 접근하였는데, 다른점은 SERP가 심볼 테이블 관리를 하는데 있다. 사용자는 명령어 인수를 명시할 때, 인수들에 대응되는 심볼 테이블 인덱스 대신 직접적인 값을 사용한다. 따라서 심볼 테이블 관리는 사용자로부터 완전히 은닉되었다고 볼 수 있다. 추가로, SERP는 심볼 테이블 인덱스와 테이블 자체를 직접적으로 조작할 수 있는 low-level 메소드들도 제공하긴 한다. 그러나 BCEL과 같이 SERP는 더 이상 사용되지 않는 상수들을 심볼 테이블에서 자동으로 제거해주진 않는다.
ASM의 접근법
ASM의 주요 아이디어는 조작하고자 하는 클래스들을 객체화하지 않는 것이다. 이는 클래스 트리 구조에 있는 다양한 노드들과 바이트코드 명령어에 대응하는 수 많은 클래스들을 정의해야 하는 것을 필요로 한다 (SERP에는 약 80개의 클래스가 있고, BCEL은 270개가 있다). 이로 인해 클래스의 역직렬화 과정에서 수 많은 객체의 생성되어 시간과 메모리를 많이 잡아먹을 것이다. ASM의 목표는 최대한 가볍고 빠른 툴이 되는 것이다.
그러나, 그렇다면 어떻게 하면 클래스의 객체화 없이, 바이트 배열 수준에서 클래스를 조작할 수 있는 high-level 인터페이스를 만들 수 있을까?
ASM이 선택한 방법은 이미 BCEL, SERP, OpenJava 등의 변환 툴에 있는 Visitor Design Pattern을 사용하는 것인데, 단, 차이점은, 방문된 트리를 명시적으로 객체로 나타내지 않는다.
이 패턴을 사용하면 직렬화된 객체 그래프를 역직렬화하지 않고 방문할 수 있다. 더 정확히 말하면 원시적 타입 값들인 숫자와 문자열 값들만 역직렬화하는 것이다. 그리고, 기존 그래프를 변경한 새로운 버전의 그래프를 객체화 없이 직렬화된 상태로 바로 만들 수 있다.
다음 예시를 통해 알아보자.
ALOAD_0 GETFIELD f 명령어 시퀀스는 this의 f 필드 값을 읽는다. Visitor를 사용하여 이를 getf 메소드를 호출하는 ALOAD_0 INVOKEVIRTUAL getf로 변환한다.
세 가지 객체가 사용된다:
Class Analyzer R은 Visitor V를 만들어 클래스를 방문하게 한다. 그리고 V는 또 다른 Visitor W를 사용하여 점진적으로 클래스를 재구성한다. 여러 개의 독립적인 코드 조작 연산들을 하나로 구성하기 위해 여러 개의 중간단계의 Visitor들을 사용할 수 있다.
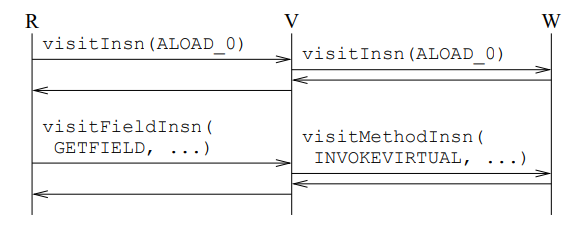
R은 바이트 배열로 주어진 원래의 명령어 시퀀스를 분석하고, 각 분석된 명령어에 대한 적절한 메소드를 V에게 호출한다.
R은 V에게 visitInsn 메소드를 정수 ALOAD_0를 매개변수로 넣어 호출한다. 그 후, V는 W에게 R에게 받은 호출을 그대로 호출한다.
그 후, R에게 다시 통제권이 오면 R은 visitFieldInsn 메소드를 정수 GETFIELD와 주체 클래스(필드가 포함되어 있는 클래스), 필드의 이름과 값을 나타내는 세 개의 문자열을 매개변수로 넣어 호출한다. 그리고나서 V는 R로부터 받은 바이트코드 명령이 GETFIELD인지 확인하고, 맞다면 visitMethodInsn를 W에게 호출하고, 아니라면 visitFieldInsn를 호출한다.
W는 점진적으로 클래스를 바로 직렬화된 형태로 재구성한다. 첫 요청에서 W는 생성하고 있는 배열의 마지막에 해당 호출(바이트코드 명령어)을 가리키는 바이트를 추가한다. 그리고 V가 visitMethodInsn 메소드를 호출했을 때도 마찬가지이지만 이 명령어는 3 바이트의 크기를 필요로 한다.
직렬화와 역직렬화
BCEL이나 SERP처럼 모든 직렬화와 역직렬화 세부 과정은 항상 ASM에 의해 관리되고 사용자는 이를 신경 쓸 필요가 없다. 더 정확히 말해서, ASM은 ClassReader 클래스를 제공하는데, 이는 바이너리 형태의 클래스를 분석하고 ClassVisitor 인터페이스를 구현하는 Visitor를 만들어서 해당 바이너리 형태의 클래스를 방문할 수 있게 한다. 또, ASM은 ClassVisitor 인터페이스를 구현하는 ClassWriter 클래스를 제공하는데, 이는 클래스를 바로 직렬화된 형태로 생성하도록 도와준다. - 각각 위 예시에서 본 R, V, W에 해당된다.
심볼 테이블 관리
ASM은 심볼 테이블의 관리를 완전히 숨긴다. 따라서 사용자는 테이블의 상수들의 인덱스를 직접 조작할 필요 없다. (위 그림의 예시에서 visitFieldInsn 메소드의 매개변수들은 방문된 필드의 소유 객체, 이름, 그리고 타입은 String 객체이지, 심볼 테이블의 상수들의 인덱스가 아니다). 더 나아가 클래스들은 현 상태에서 바로 수정되는 것이 아니고, “재빌드”를 통해 수정되므로 심볼 테이블이 사용되지 않는 상수들을 포함하지 않는 것을 보장할 수 있다.
명령어 주소 관리
ASM은 BCEL과 SERP가 하는 것처럼 바이트코드 명령어를 나타내는 Java 객체들에 대한 레퍼런스를 사용하여 명령어 주소 관리 문제를 해결할 수 없다. 왜냐하면 명령어를 객체로 나타내지 않기 때문이다. ASM은 대신 label을 사용한다 - 어셈블리어처럼 이를 Label 객체로 나타낸다.
예를 들어, 아래의 명령어 시퀀스를 보자. 로컬 변수 1을 감소시키고 그 값을 스택에 넣고, 이 값이 nul이 아닐때 까지 5 바이트 뒤의 첫번 째 명령어로 점프한다.
IINC 1 -1
ILOAD 1
IFNEQ -5
l: IINC 1 -1
ILOAD 1
IFNEQ 1
ClassReader 점프 명령어를 감지하기 위해 코드를 사전 분석하고, 필요한 label들을 계산한다 (여기선 l). 그리고 ClassReader는 바이트코드 명령어와 label들을 방문하기 위한 적절한 메소드들을 호출한다: visitLabel(l), visitIincInsn(1, -1), visitVarInsn(ILOAD, 1), visitJumpInsn(IFNEQ, l). BCEL과 SERP와 같이 명령어들의 주소는 사용자로부터 숨겨져있다. 이 툴들에서는 직렬화 단계에서만 명령어들의 주소가 새로 계산되기 때문이다 (i.e. ClassWriter 클래스 안에서). 예를 들어, ClassWriter는 l에 해당되는 절대 주소를 해당 label을 방문할 때 저장하고, IFNEQ 명령어를 방문할 때, 그에 대응되는 상대 주소를 계산한다.
IINC 1 -1
ILOAD_1
IFNEQ -4
여기서, -5 대신에 -4인 이유는 ClassWriter가 자동으로 ILOAD 1(2 bytes)을 ILOAD_1(1 byte)로 바꿨기 때문이다.
최대 스택 크기 계산
BCEL과 SERP와 같이 ASM은 메소드의 최대 스택 크기를 계산하기 위한 기능을 제공한다. 스택 크기는 control flow analysis 알고리즘을 사용하여 계산된다. 이 알고리즘은 메소드의 코드를 basic bloc (들어오는 혹은 나가는 점프가 없는 명령어 시퀀스)으로 분해하고 이러한 블록들을 그래프 형태로 연결한다. 이 때, edge는 한 블록에서 다른 블록으로의 점프를 나타낸다. 그 후, 각 블록에 대한 최대 스택 크기를 계산하고, 결과적으로 그래프를 방문함으로써 글로벌한 최대 스택 크기를 구한다.
Label 객체로 나타낸 basic bloc들과 그것들의 최대 스택 크기는 메소드 코드 방문 시 계산된다. Control flow graph 또한 그 방문 시점에 계산된다. 글로벌 최대 스택 크기는 그래프 전체, 즉 모든 명령어들을 방문함으로써 계산된다.
출처
Eric Bruneton, Romain Lenglet, Thierry Coupaye - ASM, a code manipulation tool to implement adaptable systems
Leave a comment